
AI 時代到來,數據驅動不再只是「資料多」,而是要「即時可用」。推薦系統、fraud detection、AI decision engine,這些需求都希望資料進來就能立刻用。Stream Processing(串流處理) 因此從選擇題,變成現代數據平台的必備核心能力。
相比傳統的 Batch Processing(批次處理),Stream Processing 能夠:
Streaming Pipeline(串流數據管道)是實現 Stream Processing 的完整架構體系。它包含了從數據接收、處理、到輸出的整個流程,讓我們能夠建構出穩定可靠的即時數據處理系統。
Stream Processing 的核心特色:
┌─────────────┐ ┌──────────────┐
│ Data Sources│───▶│ Message Queue│
│ │ │ │
│• App Logs │ │• Kafka │
│• IoT Events │ │• Pulsar │
│• User Acts │ │• RabbitMQ │
│• DB Changes │ │ │
└─────────────┘ └──────────────┘
┌──────────────────┐ ┌────────────┐
───────────────────▶│Stream Processing │───▶│Output Sinks│
│Engine │ │ │
│• Flink │ │• Database │
│• RisingWave │ │• Dashboard │
│• Spark Streaming │ │• Warehouse │
│ │ │• Alerts │
└──────┬───────────┘ └────────────┘
▼
┌────────────┐
│State Store │
│ │
│• RocksDB │
│• Memory │
│• Checkpoint│
└────────────┘
核心組件說明:
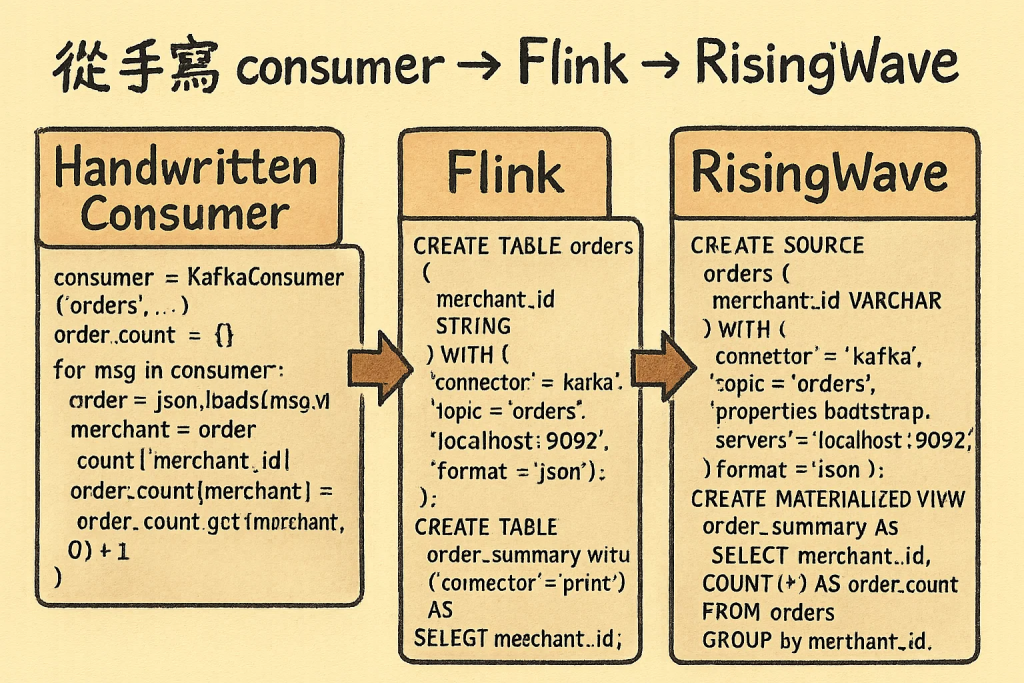
這一系列三十天文章,筆者會專注於 Stream Processing Engine 這個核心組件,用自己實際的經驗,深入探討不同 Stream Processing Engine 的特色與演進。經歷了從 手寫 Consumer → Flink → RisingWave 的技術轉變,會詳細分享每個 Stream Processing Engine 的實作心得、優缺點分析,以及選型考量。
當時團隊最初的「即時報表」解法,就是手寫 Kafka consumer。嚴格來說,這還不算是真正的 Stream Processing Engine,只是最基礎的消息消費邏輯。
consumer = KafkaConsumer(
'orders',
bootstrap_servers='localhost:9092',
)
order_count = {}
for msg in consumer:
order = json.loads(msg.value)
merchant = order['merchant_id']
order_count[merchant] = order_count.get(merchant, 0) + 1
這種方式雖然簡單,但 Kafka offset、錯誤處理、狀態維護全要自己處理,麻煩又易壞。缺乏 Stream Processing Engine 應有的 fault tolerance、state management、windowing 等核心功能。
導入 Flink 這個成熟的 Stream Processing Engine 後,事情變得專業多了。
Flink 作為業界領先的 Stream Processing Engine,幫我們處理了 Kafka offset、watermark、checkpoint 等核心功能,讓大規模 Stream Processing 變得穩定可靠。
from pyflink.table import EnvironmentSettings, TableEnvironment
t_env = TableEnvironment.create(
EnvironmentSettings.in_streaming_mode()
)
t_env.execute_sql("""
CREATE TABLE orders (
merchant_id STRING
) WITH (
'connector' = 'kafka',
'topic' = 'orders',
'properties.bootstrap.servers' = 'localhost:9092',
'format' = 'json'
)
""")
t_env.execute_sql("""
CREATE TABLE order_summary
WITH ('connector'='print') AS
SELECT merchant_id, COUNT(*)
FROM orders GROUP BY merchant_id
""")
不過 Flink 這個 Stream Processing Engine 仍需要較高的工程門檻,例如 performance tuning、cluster 部署、state backend 調整等。
最近使用 RisingWave 這個新一代 Stream Processing Engine 時,發現 Stream Processing 真的「簡化很多」。RisingWave 同樣是完整的 Stream Processing Engine,但提供了更簡潔的使用方式,只需要用 SQL 就能完成複雜的流處理邏輯。
CREATE SOURCE orders (
merchant_id VARCHAR
) WITH (
connector = 'kafka',
topic = 'orders',
properties.bootstrap.servers = 'localhost:9092',
format = 'json'
);
CREATE MATERIALIZED VIEW order_summary AS
SELECT merchant_id, COUNT(*) AS order_count
FROM orders
GROUP BY merchant_id;
相比 Flink,RisingWave 這個 Stream Processing Engine 的優勢很明顯:
對熟悉 SQL 的 data team 來說,這個現代化的 Stream Processing Engine 門檻低非常多。
從手寫 Consumer → Flink → RisingWave,這段旅程正好反映了 Stream Processing Engine 的演進趨勢:
在 AI 時代,Stream Processing Engine 會變成數據平台的核心,而選型標準也正在往「更低門檻、更快上手」方向演進。
接下來會深入探討各種 Stream Processing Engine 的技術細節、選型考量、最佳實務,以及未來趨勢,敬請期待!
您好,謝謝您這篇文章的精采分享!非常認同您提到的,在 AI 時代下 Stream Processing 已從選擇題變成現代數據平台的必備核心能力。您對 Stream Processing 核心概念的闡述,以及透過 Streaming Pipeline 架構圖對整體流程和各核心組件的拆解,都非常清晰易懂,對於想要入門或深入了解的讀者來說幫助很大。
特別是對於像推薦系統或詐騙偵測這些需要秒級決策的應用場景,即時處理能力的確是關鍵。我很期待您後續針對 Stream Processing Engine 的深入探討,尤其是不同引擎(如 Flink、RisingWave、Spark Streaming)在實際應用上的選型考量與最佳實踐。這是一個非常實用且有價值的系列!
也歡迎版主有空參考我的系列文「南桃AI重生記」:
https://ithelp.ithome.com.tw/users/20046160/ironman/8311
